We are in the age of data, we hear it repeated continuously; the mantra that resounds everywhere, from the press to the generalist sector, is always the same: BIG DATA.

Where does this large amount of data come from? And why do we talk about it so much today?
The answer is quite simple: we talk about it so much because the data have enormous economic value, especially if they concern people and their behavior.
"Data is the new oil", Clive Humby, Mathematician
We are talking about
"dynamic" data, that is, of those data that change over time, precisely because they are the digital fingerprint of our life in the world, such as passing through a place, our tastes and our opinions, our behavior and relationships with friends and brands.
And here is the answer to the first question, most of the data comes from people and devices used by them, such as smartphones, computers, wearable devices, but also from the "things" used by humans such as home automation, smart devices (washing machines) , air conditioners, automobiles, etc.) up to industrial tools, ie from the famous IoT devices (Internet of Things)
 Summing up then, the huge increase in data is due to the following factors:
Summing up then, the huge increase in data is due to the following factors:
- Today it is no longer just computers and mobile devices that are connected, but everything, even the signals of our body
- Data transport networks have reached high speeds even on the mobile
- Users have switched from one-use-to-use-based consumption model (As A Service On Demand)
Let's go back to the initial statement:
we are in the data age.
This statement is so true, that for the first time in modern history, it is technology that is chasing data, not data searching for a technology that supports and generates them. This has, in fact, traced the path of technological macro-trends in the coming years
- Big Data: understood as the ability to attract, collect, analyze and above all represent a large amount of unstructured data
- Artificial intelligence: the ability to process data with processes and performances similar to those of human intelligence
- Blockchain: the technology created to guarantee decentralization, transparency, security and immutability of data.
It is precisely on these themes that
TEIA Technologies, a company belonging to the Lutech group, focuses precisely on the data age, with the awareness that the value of the data does not lie in the data itself, but in the knowledge we can derive from it.
In TEIA we work on the data and with the data to extract, in fact,
knowledge.
Knowing your customers and prospects is no longer just a competitive advantage, but a necessity that companies can no longer ignore, and that's what we do for our customers and partners: collect and process data using the technologies we've talked about above:
Big Data, Artificial Intelligence and Semantic Analysis.
The data on which we work are mainly divided into two macro categories:
- Open data: all data available on public socio-digital channels, such as Social Networks, Forums and Blogs
- Custom Data: the data that are present in the company, and that almost always are a mine of information not carried to value.
Since its foundation in 2013, TEIA has developed and put various products and services in a portfolio, thanks to continuous technological research and collaboration with major universities and research institutions:
- AI: proprietary artificial intelligence platform, based on machine learning, neural networks and cognitive computing
- Topic Catcher: semantic clustering (http://topic.teia.company)
- Custom Data Analyzer: platform dedicated to the analysis, also in real time, o customer custom data, also based on the technological core of teia.ai
- Opinion Platform: proprietary opinion analysis platform based on teia.ai.
The
Opinion Analysis platform is, in fact, the central cornerstone of the company's proposal in the context of
Social Analytics. Its main strength is expressed in the ability, enabled by the synergistic use of different AI technologies and semantic analysis, to distinguish between
sentiment and
opinion, a substantial difference when we want to extract granular and quality information from the analysis of data "
Increasingly, Sentiment and Opinion Analysis are used as synonyms to such an extent that even on Wikipedia the definition of Sentiment Analysis reads: "Sentiment analysis (also known as opinion mining) refers to the use [...]".
The differences, however, are substantial because identifying the mood of a text is a very different operation than deriving its opinion. Let's try to think of the following sentence:
"These cookies are delicious".
It is quite simple to attribute the correct mood that, in this case, is "POSITIVE" but if the sentence to be analyzed was the following, what would be its mood?
"This brand makes delicious cookies, but they are full of fat and cost too much."
Most of the Sentiment Analysis tools would force the attribution of a label through an algorithm based on generic rules of semantic interpretation and, at best, to a text like that of the example would attribute a "
NEUTRAL" mood (it could, however, happen that the label assigned is that of "
POSITIVE").
It is evident that the result not only does not perfectly reflect reality but provides indications that are potentially the opposite of the real expressed sentiment.
The forcing in attributing a mood "at all costs" is one of the main reasons why in the majority of sentiment analysis the percentage of neutrality is very high (above 60-70%), this type of result should be an alarm for those who receive it: on social networks people write to express their opinions or to share information, it is therefore strange to conclude an analysis of this type stating that most of the posts are labeled as "
NEUTRAL".
The fault of this result is not (only) to be attributed to the tool or the algorithms used in the analysis: try to attribute a sentiment to the offending sentence. I am convinced that most people, at the question "What mood would you attribute to the above sentence?" Would answer “It depends".
Here, this is the problem: an analysis tool can not answer "
DEPENDS", and without precise instructions can not help but force an answer, even if clearly wrong.
Let's try to analyze the previous sentence by placing a well-defined condition: what we would answer if the question were asked as follows: "What is the opinion about the price of cookies?" or "What is the opinion about the taste of cookies?"; in this case, I am sure, the answer would not be “
IT DEPENDS" but a very precise label or category.
Well, the accuracy of the answers is one of the substantial differences between Sentiment Analysis and Opinion Analysis, but it is obviously not the only one.
When we ask someone's opinion, we expect a reasoned answer or otherwise the precise expression of a personal thought. I try to explain once again with an example, to the question "Why do you like these cookies?" What do you expect to be answered? Something like "positive perception" or a structured comment as it could be: "These cookies I like because they know about butter"?
Here is another difference between Sentiment Analysis and Opinion Analysis: in the first case, the maximum we can get is a more or less precise representation of the mood around a single and well-defined topic, while in the second case we can get the answers to our questions.
As an example, below we show a possible representation of an opinion analysis. In this case, the analysis refers to the user's perception of the assistance services of a manufacturing company operating in consumer electronics:

As you can see, regardless of the specific case, the Opinion Analysis allows us not only to determine the mood but also, and above all, to understand the motivations behind it.
One of the greatest difficulties in listening to the network is to be able to separate what is an opinion, from what is instead a simple news, ie a post or article that does not express opinion, but that simply shares information, or from communications of the same brand that you want to derive the perceived.
Also in this case the simple Sentiment Analysis is not enough, to understand what opinion the people have of our brand, product or service, but it is necessary to rely on the Analysis.
The image below shows the graphic effect of the approach described above applied to a survey conducted during the launch of a consumer product:
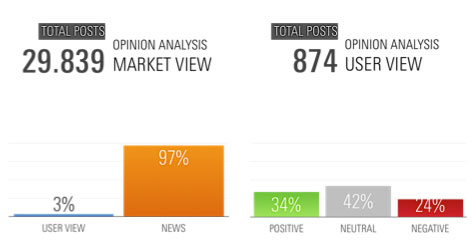
The first thing that is evident is how the volumes at stake are drastically different and how, above all, the number of posts in which users express a real opinion about a particular topic is very less than the number of posts that report generic information but that do not represent the expression of end users, but that is what every brand wants to know when analyzing the opinion of its customers and prospects.
The next steps: customers are people, who leave a footprint when they interact with the digital and physical world: they give, sometimes unconsciously, enormous information about their behavior and habits, which can tell us a lot about their personality. It is with this awareness that we are developing a proprietary platform for the analysis of psychometric personality traits. Soon we will be able to tell you that the psychological profile has a person who interacts with certain contents, so as to better calibrate the communication addressed to it.
Teia is also very attentive to the security of the data it deals with, so we could not even start working on the blockchain, studying and developing systems for decentralization and information security.
Mauro Ferri
Co-Founder TEIA, Lutech Group